Hyperparameter Tuning in Machine Learning: Boost Your Model’s Performance
Machine learning models have become powerful tools for solving problems across domains like healthcare, finance, retail, and technology. However, building an effective model is not just about choosing the right algorithm—it’s also about setting the right hyperparameters. Hyperparameter tuning is the process of finding the best configuration of these parameters to improve model performance. In this blog, we’ll explore what hyperparameters are, why tuning matters, common tuning strategies, and a hands-on example with Python.
What Are Hyperparameters?
Hyperparameters are the settings of a machine learning algorithm that are not learned from the data but must be specified before training. They define how the learning process takes place. Examples include:
- Learning rate in gradient-based algorithms
- Number of trees in Random Forest
- Maximum depth in decision trees
- Regularization strength in logistic regression
In contrast, parameters (like weights in linear regression) are learned during model training.
Choosing poor hyperparameters can lead to underfitting (model too simple) or overfitting (model too complex). Proper tuning ensures a balance and maximizes predictive power.
Why Is Hyperparameter Tuning Important?
- Performance Boost: The same algorithm can perform very differently with different hyperparameters.
- Generalization: Well-tuned models generalize better on unseen data.
- Efficiency: Some hyperparameters affect computation time. For example, fewer trees in Random Forest speed up training but may reduce accuracy.
- Model Comparison: Fairly comparing algorithms requires tuning each properly.
Without tuning, you risk drawing incorrect conclusions about which model is “better.”
Common Hyperparameter Tuning Techniques
Manual Search
- Trying different values based on intuition or prior experience.
- Simple but time-consuming and biased.
Grid Search
- Exhaustively searches over a predefined set of hyperparameter values.
- Guarantees the best result within the grid but can be computationally expensive.
Random Search
- Samples random combinations of hyperparameters.
- Surprisingly effective and often faster than grid search.
Demonstration: Hyperparameter Tuning with Decision Tree
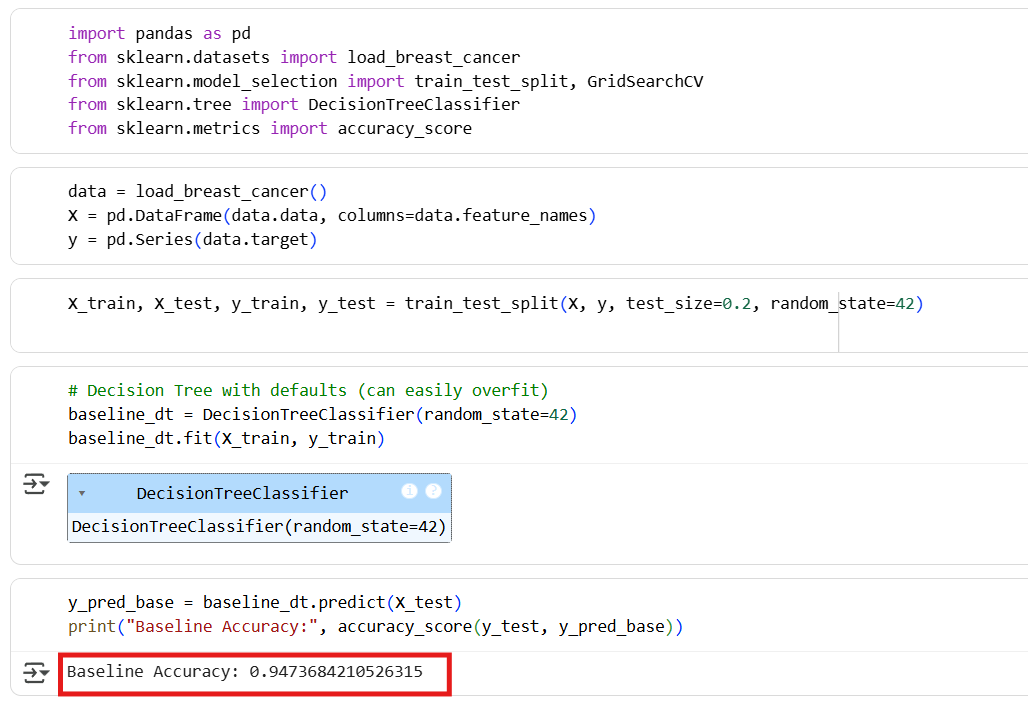
We’ll use the Breast Cancer dataset and compare performance before and after tuning.
Baseline Model
Hyperparameter Tuning
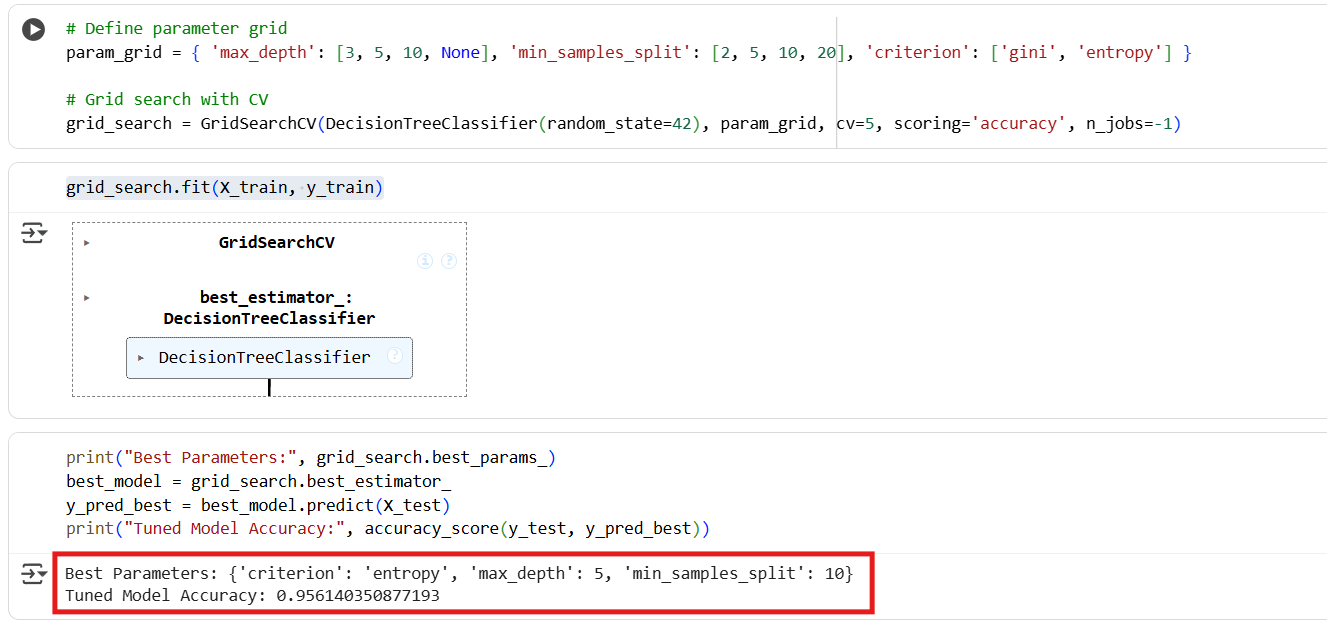
Key Takeaway
- Baseline Decision Tree Accuracy: 0.9473
- Best Parameters:
{'criterion': 'entropy', 'max_depth': 5, 'min_samples_split': 10} - Tuned Decision Tree Accuracy: 0.9561
That’s about a 1% absolute improvement. While the gain isn’t huge, it clearly shows how tuning can squeeze out extra performance by finding a more balanced tree (optimized depth, splits, and criterion). Even small improvements matter in real-world applications.
Best Practices in Hyperparameter Tuning
- Start Simple: Begin with a small parameter space before expanding.
- Use Cross-Validation: Prevents overfitting by evaluating performance across folds.
- Balance Accuracy and Speed: More parameters may improve accuracy but increase training time.
- Domain Knowledge Helps: Understanding the data and algorithm can guide which parameters to tune.
Conclusion
Hyperparameter tuning is a critical step in building effective machine learning models. While the algorithm choice matters, tuning often makes the difference between mediocre and excellent performance. Methods like grid search and random search give us systematic ways to find optimal configurations.