Poor Data Quality in Machine Learning: Why It Happens and How to Fix It
Machine learning models are often judged by their algorithms, accuracy scores, and complexity. However, experienced data scientists know that data quality matters more than the algorithm itself.
In fact, many machine learning failures are not caused by bad models but by poor quality data.
What is Poor Data Quality in Machine Learning?
Poor data quality refers to datasets that contain errors, inconsistencies, missing values, duplicates, or incorrect labels.
Machine learning models learn patterns from the data they are given. If the dataset contains unreliable information, the model will learn incorrect patterns.
This leads to:
- Low prediction accuracy
- Biased models
- Poor generalization to new data
Common Data Quality Problems in ML
1. Missing Values
Missing values occur when certain entries in a dataset are empty.
Example
| Age | Salary | Experience |
|---|---|---|
| 25 | 50000 | 2 |
| 30 | NaN | 5 |
If too many missing values exist, the model may struggle to learn meaningful patterns.
Common solutions include
- Removing rows with missing values
- Filling values with mean or median
- Using model-based imputation
2. Duplicate Data
Duplicate records appear when the same data is stored multiple times.
Example:
Customer records repeated in a dataset.
Duplicates can:
- Bias the dataset
- Make certain patterns appear more frequently than they actually are
Removing duplicates ensures that the dataset represents true real-world distribution.
3. Incorrect Labels
In supervised learning, labels define the correct answer.
Example:
Image of a cat labeled as dog.
When labels are wrong, the model learns incorrect relationships.
This is one of the most dangerous data problems in machine learning.
4. Inconsistent Data Formats
Datasets sometimes contain inconsistent formats such as:
Date column example
2024/01/10
10-01-2024
Jan 10 2024
Models require consistent structured data.
Cleaning and standardizing formats is an important preprocessing step.
Why Data Quality is Critical for ML Models
High quality data improves:
Model Accuracy
Clean datasets help models detect correct patterns.
Generalization
Models trained on good data perform better on unseen data.
Training Stability
Noise and errors can confuse algorithms and increase training time.
Many ML experts say:
80% of machine learning work is data preparation.
Data Cleaning Techniques for Machine Learning
Handling Missing Values
Common techniques include:
- Mean Imputation
- Median Imputation
- Forward Fill
- Dropping rows or columns
Example in Python
import pandas as pd
df['attendance'] = df['attendance'].fillna(df['attendance'].mean())
Removing Duplicates
df = df.drop_duplicates()
This ensures every observation is unique.
Fixing Data Types
df['date'] = pd.to_datetime(df['date'])
Standardizing formats helps models interpret features correctly.
Detecting Outliers
Outliers can distort training results.
Techniques include:
- Z-score method
- IQR method
- Isolation Forest
A Simple Experiment: How Data Cleaning Improved My Model Performance
To understand how data quality affects machine learning models, I conducted a small experiment using a simple student performance dataset.
The dataset contained the following features:
- study_hours – number of hours a student studied
- attendance – percentage of classes attended
- previous_score – previous exam score
- final_score – final exam score (target variable)
However, the dataset intentionally contained several data quality issues, including:
- Missing values
- Duplicate rows
- Invalid values (e.g., attendance greater than 100%)
- Incorrect scores (negative values)
These issues simulate real-world datasets, which are often messy and require preprocessing before training machine learning models.
Training the Model Without Data Cleaning
First, I trained a Linear Regression model using the raw dataset without performing any data cleaning.
The goal was to observe how poorly structured data impacts model performance.
Result
| Model | Dataset | R² Score |
|---|---|---|
| Linear Regression | Raw Data | -1.18 |
A negative R² score indicates that the model performed extremely poorly.
This happened because the model attempted to learn patterns from incorrect and inconsistent data.
For example:
- Missing attendance values confused the model
- Invalid attendance values (greater than 100) distorted relationships
- Negative exam scores created unrealistic patterns
- Duplicate rows biased the dataset
As a result, the model could not learn meaningful relationships between the features and the final score.
Cleaning the Dataset
Next, I performed basic data cleaning steps:
- Handled missing values by filling them with the average attendance value
- Removed duplicate rows to avoid biased learning
- Filtered invalid records such as:
- Attendance values above 100%
- Negative exam scores
These steps ensured that the dataset represented realistic and consistent information.
Training the Model After Data Cleaning
After cleaning the dataset, I trained the same Linear Regression model again using the cleaned data.
The difference in performance was dramatic:
| Model | Dataset | R² Score |
|---|---|---|
| Linear Regression | Cleaned Data | 0.96 |
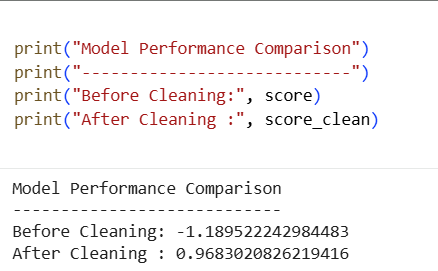
The R² score improved from -1.18 to 0.96, showing a massive improvement in prediction accuracy.
Model Performance Comparison
Download the dataset and notebook here.
Key Insight
This experiment clearly demonstrates an important principle in machine learning:
Better data often matters more than a better algorithm.
Even a simple model like Linear Regression can perform extremely well when trained on clean, reliable data.
Final Thoughts
Poor data quality is one of the most common challenges in machine learning.
Even the most advanced algorithms cannot compensate for unreliable data.
By focusing on:
- Data cleaning
- Handling missing values
- Removing duplicates
- Fixing incorrect labels
you can significantly improve model performance.
Always remember:
A good dataset is the foundation of a successful machine learning model.